In the world of MicroServices, new services get deployed every day and it is hard to keep track of these new services and it is hard for a centralized Ops team to add alerts for each and every service. So we depend on Service Owners to add the alerts for their services but it is never a good idea to depend on a human when it can be easily automated. We use NewRelic for monitoring these services. NewRelic provides ways for achieving this partially by Dynamic Targeting.
Dynamic Targeting
Instead of adding policies for each app, we can use the NewRelic tags to create conditions that can trigger alerts.

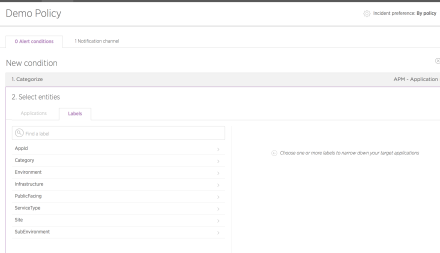
Creating a condition specific to labels like Environment, Sub-Environment, Site and public facing etc., helps us to add conditions to new Services dynamically. Any Service with specific labels will have these conditions attached automatically by NewRelic which is a good thing. These tags can be attached to those services using the NewRelic configuration YAML file.
Dynamic Alert Policies
We found the Dynamic Targeting by NewRelic pretty good but it haven’t met all our requirements. Some alerts related to Error rate, APDEX score, Web Response time all these were service/application specific. These are hard to determine and set to a specific value. So we went ahead and used NewRelic API to achieve our requirements. We built our own orchestrator that deploys these services which helps us achieve these things. We used the functionality of NewRelic Events, NewRelic API, SQS and our own service that add these Alert Conditions dynamically for each deployment.

We built in house orchestrator for all the deployment purposes. This can be used to add alerts post deployment but we want to do things in MicroService world, so we built our own NewRelic MicroService to do this work for us and let our Orchestrator concentrate on it’s main purpose. This NewRelic Service listens to the SQS for deployment events and adds alert policies based on the metadata of the new service from GIT ( SVN to store all metadata of the applications such as AWS app / DataCenter app, ports, UI/API etc., APDEX score, Expected Response Time etc.,). These are saved in github, so we can track these changes and any changes done in the github can trigger an event to dynamically trigger the NewRelic Service to modify the values based on the updated metadata in git. This NewRelic Service is also used to scan or clean up non-reporting AWS Servers/ APM’s which are shown as hidden in NewRelic and some other purposes. We used RxJava to build this Service. This helped us to achieve fully automated alert policies without any manual intervention. We also send email notifications if we see any service that is not attached to a policy. There is not direct API to determine this, so we used our new scanner service which I will discuss in our coming posts.
